15 things I’ve learned doing serverless for a year and a half
At Seattle Cancer Care Alliance (SCCA) we have been transitioning two monoliths into the serverless architecture. A year and a half in and it absolutely feels like the right direction. I have learned a lot along the way, here are 15 things I’ve learned.
This has been in Aws which is what this article will largely focus on but many of the lessons are likely applicable to other cloud providers.
A Cloud Guru posted a similar article here. I think everything in that article is right! But my own list is a little different.
1. Use the Serverless Framework
You can find it here. It is a fantastic tool. My only real complaint is that its name is bit misleading. I̵t̵’̵s̵ ̵a̵ ̵f̵r̵a̵m̵e̵w̵o̵r̵k̵ ̵t̵h̵a̵t̵ ̵r̵u̵n̵s̵ ̵o̵n̵ ̵y̵o̵u̵r̵ ̵l̵a̵m̵b̵d̵a̵s̵.̵.̵.̵
The Serverless Framework is a deployment tool that makes deploying your serverless archtecture a breeze. Once configured, you can deploy serverless architectures like the example below with a single command (serverless deploy).

The Serverless Framework is built on top of cloud formation so you can pretty much deploy and wire up any Aws service. It also helps you manage your lambda permissions and versions. Using the Serverless Framework enables you to develop, test and deploy your application in a whole new way (more on this later).
See here for more about building a pipeline with the Serverless Framework.
2. You can build almost anything
When you first start reading about serverless archtecture you will encounter a lot about its limitations, much of this information is not correct. This is in large part because Aws and other cloud providers are investing heavily into serverless, and many things that used to be difficult/impossible are now very easy.
For example, running a lambda on a schedule used to be very difficult. Now you can just set up a cron job in cloud watch. The Serverless Framework can even do this for you!
We have built etl processes, application api and utility services. We have one process, processing about 500 messages a minute and another that processes 50k once a week. The serverless archtecture handled both of these with ease and could be scaled up if needed (more about performance later).
One of the biggest concerns about using serverless is the cold start. It is true that the first time you call your lambda it takes about a second longer, but in practice this doesn’t affect much. The reason for that is:
- When processing lots of data an extra second doesn’t add much time.
- If your api is getting enough use, the extra second is going to be rare.
Even websockets are possible now! (Worth noting the framework now supports it as well).
The only thing I wouldn’t recommend serverless for is high performance computing (for which you shouldn’t use the cloud at all).
3. You can cache and use connection pooling
One common misconception is that lambdas spin up every time they are called. Lambdas run inside of a container. When your lambda is done Aws doesn’t destroy the container, they freeze it. This is why the cold start time only affects the first call. This means you can share data and resources across lambda invocations. Ca-ching let the cache flow!
There are a couple things to note:
1. Aws reserves the right to kill the container at any time (and they do kill them off usually in the order of hours). If you have built a native app this is similar to how Android and iOS manage memory.
2. Aws spins up a container per concurrent invocation, so you can’t share resources across concurrent calls. This is best thought of as container pooling :).
Neither of these are caching deal breakers. Use of caching and resource sharing greatly increase performance. One big gain is in using connection pooling. You can share established connections between calls.
For more about how to build a cache for node see my post here.
4. You need to be careful using connection pooling
As noted above you can use connection pooling with serverless archtecture. But you need to be a little careful because Aws spins up a container per concurrent call. Because I didn’t understand how this worked I accidentally spun up ~1000 connections (oops). This was easily resolved by giving the lambda a connection pool size of 1. In this case it was designed to be run with high concurrency.
You need to think about how your lambdas will be run. In many cases you will want a larger connection pool. If you plan to have high concurrency keep your pool size small.
5. Lambdas can be very performant if optimized
In general horizontal scaling is better than vertical scaling and lambdas are excellent at horizontal scaling. Lambda will fire off more concurrent calls as needed. Each lambda call can also be optimized and, if done right, this can lead to very high performance.
Let’s start with an example. We needed to move 50k records once a week (not a very big load). We decided to use sqs and kick off lambdas using a batch event of 10 (this is the max). After some configuration the average execution time is ~2ms.
That is 500 calls a second per lambda. But we aren’t just running one lambda, we are running up to 1000 at once (the default limit per Aws account but this can be increased).
This is up to 500k calls a second or a billion calls in 30 mins. And this doesn’t even take the batching into account. Obviously this is way more than we needed for processing 50k records but we didn’t do a lot of extra work to get this blistering performance.
Optimizing lambdas mostly comes down to:
1. Balancing the amount of work each lambda does
2. Caching and resource sharing (don’t be afraid to load entire tables into memory)
3. Managing the amount of concurrency both in how many times your lambda will be called but also how much concurrency it uses internally. If you go with high lambda concurrency you may want to limit the amount of concurrency inside your lambda.
4. Managing how the lambdas get called; take advantage of queues and other triggers
6. Converge on one language (JavaScript)
At first we built lambdas using Python, Java and JavaScript. The thinking was that each lambda is small and can interact easily with lambdas written in different languages.
This ended up being a mistake. As we got more into the thick of things, two things became apparent:
- Lambdas often ended up bigger than we first expected
- We ended up writing the same code over and over again
About 6 months in we decided to converge on using JavaScript. This let us more easily share code across lambdas (more on this later).
There is a lot of debate about the best language for lambdas, mostly between Python and JavaScript. I prefer JavaScript but there are some compelling reasons to choose Python. But whatever you decide, pick one language and go with it.
7. Consider services as a collection of lambdas (and other Aws services)
We group our lambdas into services. This has a number of advantages:
- It reduces the overhead of infrastructure, as all lambdas in a service deploy together. This means fewer pipelines to build and releases to manage
- Lambdas that are tightly coupled get deployed together (with the other Aws services they use)
- Lambdas within a service can easily share code
- Services are black boxes to the rest of the applicationFor examp,
For example we have an auth-service which has 5–6 lambdas in it, all of which deal with authentication and authorization (once complete this will likely have 20 or so).
8. Integration test your whole serverless architecture
As you take more advantage of cloud services, integration testing can be challenging (at first). Many people try to use mock Aws services locally. And there are lots of tools for this. I don’t recommend this. Mocked services will never be exactly like the real deal.
Instead we can take advantage of the cool deployment tools we are already using. We use the Serverless Framework to deploy our services to a dev account and test our service in actual Aws. For example:
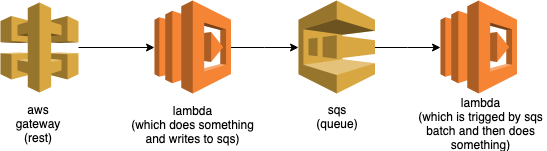
If this is what we want to test. In our pipeline we deploy a new instance of the above to our dev account. We then put it through the wringer, calling the rest endpoint or interacting with whichever service we want. This lets us test the service running in its native environment. No mocks, no fakes and no gimmicks means no surprises later on.
And when the tests are done running? We can do serverless remove which will bring down the entire service. I will likely do a whole post on this in the future.
9. it is ~1000x cheaper
There isn’t that much to say here other than that lambdas are in practice about 1000 times cheaper than using EC2’s. And this makes sense, most of the time your dedicated instances are not being fully used (but you are fully paying for them).
There are some additional considerations, such as going serverless isn’t just about using lambdas. Additional costs come from increased use of other services (don’t just use kinesis for everything) and cloudwatch is more expensive than it seems. But overall serverless will be good for your bottom line.
10. Iterative deployments make for nice development
One of the more surprising things is that I have changed the way in which I develop. I now iteratively deploy my own env to Aws. And execute my code in a real context. No hacky localhost server with env variables stuffed into a file called local.env. No more “well it works on my computer.” And this is surprisingly freeing and also quite enjoyable.
As a bonus you end up with good logging. Because you come to rely on cloudwatch over a debugger. And through small iterations and automated tests you end up with very few bugs :)
11. Event-driven architecture has some nice advantages
Amazon services are built around an event-driven architecture. At this point almost all Aws services issue events which can act as a trigger to lambda. This plays a large role in serverless architecture and has some big advantages.
The biggest benefit is that your architecture can be very loosely coupled. If a lambda is triggered by sqs it doesn’t need to know anything about sqs. Which means if you want it to switch sqs to kinesis it shouldn’t require any lambda code changes.
Unfortunately this isn’t exactly how things work but it’s close. Although Aws is built around an event-driven architecture, there are subtle differences in what the lambda gets depending on how it is called.
Even still there is a lot to take advantage of here.
With this aim in mind, always create handlers to separate the Aws logic from your business logic.
12. Some things don’t play nice with cloud formation (dns and kms)
One of the few gotchas on this list. Although you can safely build out most of your infrastructure in the Serverless Framework/Cloud Formation there are a few things that should be done by hand. We tried creating kms keys as part of our deployments but it was a nightmare. Once we committed to managing kms keys by hand everything went much smoother.
Same thing with dns in route 53. Although we found a plugin that could manage to create it, it struggled to update properly and caused our deploys to fail about 20% of the time. We ended up removing it altogether and things have gone much smoother ever since.
I guess the real lesson here is don’t aim for 100% infrastructure as code. Although it is a great goal, 90% will do you just fine. We wasted a lot of hours fighting for that last 10% only to give up in the end, and now we are at peace.
13. Use parameter store/secrets manager
At first we managed our env vars right in serverless and gitlab. But it became fairly unmanageable. There was another problem too. We couldn’t change any env vars without redeploying or causing our lambda to drift from our infrastructure as code.
So now we are using parameter store but secrets manager is an option too, or just a db table, pick your poison.
We load all the lambda settings from parameter store and cache them for 5 minutes. This has simplified our deployments and hasn’t slowed down the lambdas. And now as a bonus if we make setting changes the lambda will pick them up and adjust within 5 minutes.
Word of warning, both parameter store and secrets manager are not very nice to use. I ended up writing a utility to make parameter store more manageable.
14. Use private packages
As mentioned earlier we have ended up writing a lot of boiler plate code in our serverless services. So I created a few private npm packages. The main one handles caching, settings, logging, Aws proxies and some utility code. We have additional packages for managing Sequelize (no migrations). Even though lambda do end up being small, these libraries greatly reduce the code needed for us to get a new service up and running.
I did look into lambda layers but found creating our own packages was a better solution for what we are trying to do. There are more 3rd party libraries which are starting to come out. Lambcycle, for example, seems interesting, but doesn’t quite address the needs we have.
15. Standardize your responses
As we moved to using private packages, one of the things we did was standardize our responses from our lambda functions. This simple change has had a bigger impact than expected. As our serverless landscape grows, knowing exactly what to expect makes it much easier to consume en masse.
This is what we ended up with:
{
status: string
message: string
data: object
}Nice and simple :) Here are the statuses we use.
{
Success: 'success',
Skipped: 'skipped',
BadRequest: 'badRequest',
NotAuthenticated: 'notAuthenticated',
Unauthorized: 'unauthorized',
Error: 'error',
NotImplemented: 'notImplemented'
}In the case of rest we map these statuses to http statuses and set the body to the response object into the body.
Conclusion
I have learned a lot in the last year and half. This list is really just the highlights. It has been a blast! I can’t recommend serverless architecture more highly.
If you liked this and want me to write more about serverless please hit the clap. If you have any questions about any of this don’t hesitate to reach out.
15 things I learned doing serverless for a year and a half was originally published in Paul Heintzelman on Medium, where people are continuing the conversation by highlighting and responding to this story.



















